![Dstl Satellite Imagery Kaggle Competition, 3rd Place Winners' Interview: Vladimir & Sergey]()
In their satellite imagery competition, the Defence Science and Technology Laboratory (Dstl) challenged Kagglers to apply novel techniques to "train an eye in the sky". From December 2016 to March 2017, 419 teams competed in this image segmentation challenge to detect and label 10 classes of objects including waterways, vehicles, and buildings. In this winners' interview, Vladimir and Sergey provide detailed insight into their 3rd place solution.
![]()
The basics
What was your background prior to entering this challenge?
My name is Vladimir Iglovikov, I work as a Sr. Data Scientist at TrueAccord. A couple years ago I got my PhD in theoretical physics at UC Davis, but choose not to go for postdoctoral position as most of my colleagues. I love science, I love doing research, but I needed something new, I needed a challenge. Another thing is that I wanted to get deeper experience with software engineering and data science which would aid me in my research. A few months before my graduation, in one of the online classes at Coursera lecturer mentioned Kaggle as a platform to practice your machine learning skills. First few competitions were epically failed, but I learned a lot. Slowly, piece by piece, I was able to merge theoretical knowledge from courses, books and papers with actual data cleaning and model training. During the first year I figured out how and when to apply classical methods like Logistic Regression, SVM, kMeans, Random Forest, xgboost, etc. Neural Network type competitions were rather rare and I did not have a chance to practice deep learning that much, but starting from December of the last year we already had seven computer vision problems. DSTL problem had the closest deadline and that is why I decided to join.
Sergey Mushinskiy
I had 10+ years experience in IT, until recent switch to machine learning and software development.
I was in search for a great project to showcase my machine learning skills (especially deep learning part of it). And what could be better than winning a tough competition like this? There were several competitions on Kaggle at that time and it was a difficult choice to make – everything looked very interesting.
DSTL competition had the closest deadline, there were some technical challenges, and until the very late, notably less people than usual participated in the competition.. It was interesting to take this challenge that scared off even the top kagglers. However, during this competition it became obvious that there were a lot of extremely talented participants who did a good job and shared endless insights and solved a lot of challenging aspects.
But all this pale in comparison with encouragement coming from friends in our Russian Open Data Science community. It is a group of like-minded and extremely dedicated people, who decided to go all-in into this competition and who gave me support and motivation to start and persevere through all the challenges.
![]()
Let’s get technical
We tried to tackle this problem in a variety of different ways and, as expected, most of them didn’t work. We went through a ton of a literature and implemented a set of different network architectures before we eventually settled on a small set of relatively simple yet powerful ideas which we are going to describe.
On the high level we had to solve an image segmentation problem. Ways to approach it are well known and there is number of papers regarding the topic. Also Vladimir already had experience with this kind of tasks when he participated in an Ultrasound Nerve Segmentation competition and placed 10th out of 923.
What was the data? Unlike the other computer vision problems where you are given RGB or grayscale images, we had to deal with the satellite data that is given both in visual and lower frequency regions. On one hand it carries more information, on another it is not really obvious how to use this extra data properly.
![]()
Data was divided into train (25 images) and test (32 images) sets.
Each image covers 1 square kilometer of the earth surface. The participants were provided with three types of images of the same area: a high-resolution panchromatic (P), an 8-band image with a lower resolution (M-band), and a longwave (A-band) that has the lowest resolution of all. As you can see from the image above, RGB and M-band partially overlap in the optical spectral range. Turns out that RGB was itself reconstructed at the postprocessing step from a combination of a low resolution M-band image and high resolution panchromatic image.
- RGB + P (450-690 nm), 0.31 m / pixel, color depth 11bit;
- M band (400-1040 nm), 1.24 m / pixel, color depth 11 bit;
- A band (1195-2365 nm), 7.5 m / pixel, color depth 14 bit.
Another interesting fact is that our images have color depth of 11 and 14-bit instead of a more common 8-bit. From a neural network perspective it is better, each pixel carries more information but for a human it introduces additional steps required for visualization.
As you can see input data contains a lot of interesting information. But what is our output? We want to assign one or more class labels to the each pixel of the input image.
- Buildings: large buildings, residential, non-residential, fuel storage facilities, fortified building;
- Misc. man-made structures;
- Roads;
- Track - poor/dirt/cart tracks, footpaths/trails;
- Trees - woodland, hedgerows, groups of trees, stand-alone trees;
- Crops - contour ploughing/cropland, grain (wheat) crops, row (potatoes, turnips) crops;
- Waterways;
- Standing water;
- Vehicle (Large) - large vehicle (e.g. lorry, truck,bus), logistics vehicle;
- Vehicle (Small) - small vehicle (car, van), motorbike.
![]()
The prediction for each class was evaluated independently using Average Jaccard Index (also known in literature as Intersection-over-Union), and the class-wise scores were averaged over all ten classes with equal weights.
![]()
![]()
Overall, the problem looks like a standard image segmentation problem with some multispectral input specificities.
![]()
About the data
One of the issues that participants needed to overcome during competition is a lack of training data. We were provided 25 pictures, covering 25 square kilometers. This may sound like a lot, but these images are pretty diverse: jungles, villages and farmland. And they are really different. This made our life harder.
Clouds are a major challenge for satellite imaging. In the provided data, however, clouds were presented rather as an exception than a rule. So the issue did not affect us as much.
The fact that we did not have access to the images of the same area at different time was a big complication. We believe that temporal information could significantly improve our model performance. For instance pixel wise difference between images of the same area corresponds to an object that can change its position with time making it possible to identify moving cars.
Another interesting thing is that satellite takes a shot in such a way that in the M-band, channels 2, 3, 5 and 7 come a few seconds later than 1, 4, 6 and 8 which leads to a ghosts of a moving objects:
![]()
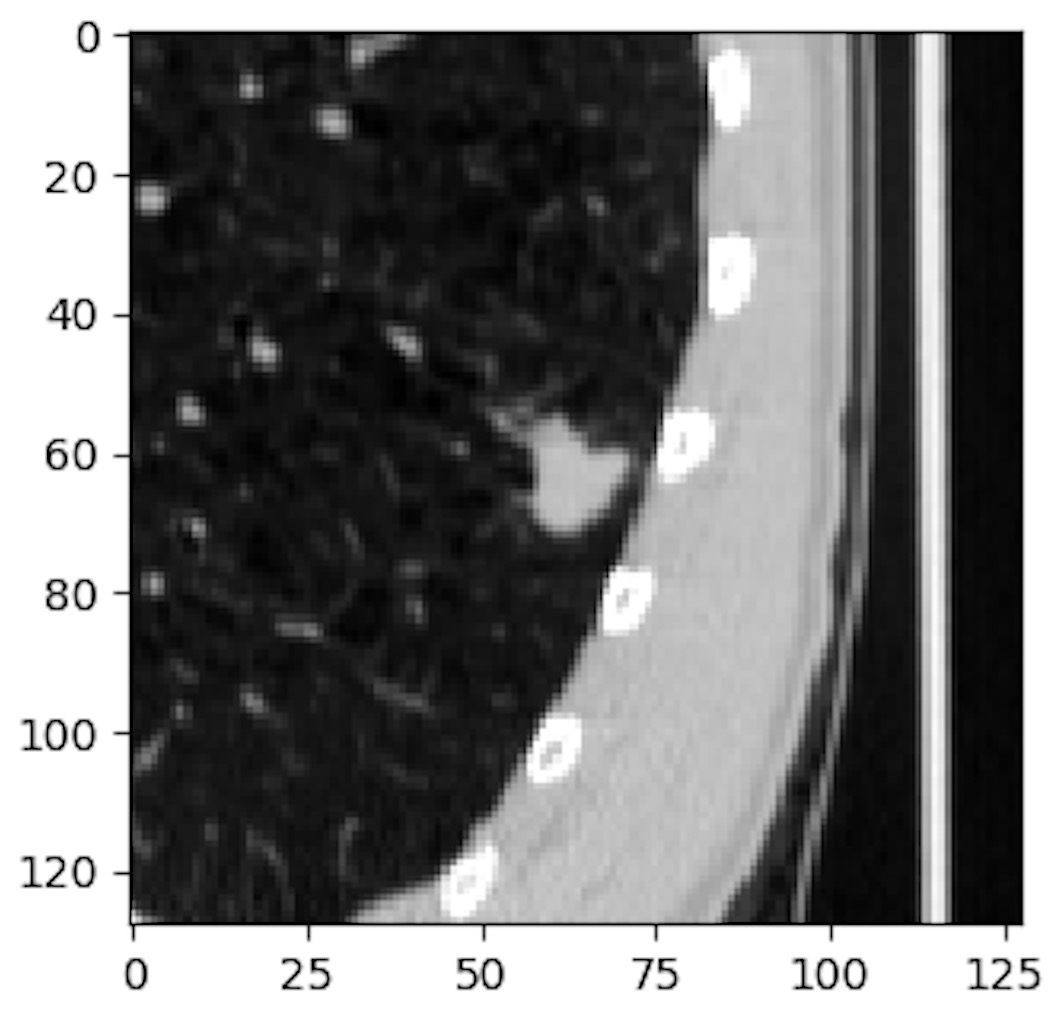
Speaking of cars, they were often labeled unreliably. The image below shows the reference annotation of cars. Needless to say, that a fraction of this reference data corresponds to unrelated objects: debris, random road pixels, etc:
![]()
As a result of all these complications we gave up on the both vehicle classes and did not predict them in our final solution. There were a few approaches that we wanted to try, like constrain the phase space to villages and roads and run FasterRNN or SSD to localize the cars, but we did not have time to implement it.
Now when we are done with an introduction we would like to present a set of ideas that helped us to finish at the third place.
First idea: Class distributions
A stable local validation is 90% of the success. In every ML textbook one can find the following words: “Assuming that train and test set are generated from the same iid…”, followed by a discussion on how to perform cross-validation. In practice, both in industry and in competitions, this assumption is satisfied only approximately, and it is very important to know how accurate this approximation is.
Class distribution in the training set can be easily obtained from the annotation data / labels. To find out how much area each class occupies in the test set we used the following trick:
For each class we made a dedicated submission in which all pixels were attributed to that class only. A jaccard score returned by the system for such submission gave us the relative area of the class in the public fraction of the test set. This approach worked because of the specific submission and evaluation formats of this particular competition (recall that the final score is an average of the classes scores, so a submission with just one class presented would give a score for this class). In addition, when the competition was over, we used the same trick to obtain distributions of the classes in images of the private fraction of the test set.
![]()
First of all, this plot tells us, that classes are heavily imbalanced within each set of images. For example, one pixel of both large and small vehicle classes corresponds to a 60,000 pixels with crops. This lead us to a conclusion that training a separate model per class will work much better than a one model that predicts all classes at a time. Of course we tried to train such a model and it works surprisingly well. We we able to get in a top 10% but not more.
Secondly, the distributions themselves vary significantly from one set of images to another.
For instance, an initial version of the train set did not contain any images with waterways, and only after competitors pointed that out, the organizers moved two images of rivers from the test into the train set. One can see that this particular class was still under-represented in the train set compared to the public and the private test sets. As a result simple unsupervised methods for water classes worked better than neural network approaches.
It is also important to mention that when train and test sets are relatively different those that participated in the competition after results on the Private Leaderboard are released change their standing a lot (in this problem participants in the middle of the Leaderboard easily moved +- 100 places). And those that did not, as usual, claimed that participants are overfitters that do not understand machine learning and do not know how to perform cross validation properly.
Second idea: water classes
These days for the most of the computer vision problems neural networks are the most promising approach. What other methods can one use for the satellite image segmentation? Deep Learning became popular only in the last few years, and people have worked with satellite images for a much longer time. We discussed this problem with former and current employees of Orbital Insight and Descartes Labs plus we read a ton of literature on the subject. Apparently fact that we have infrared and other channels from non-optical frequency range allows to identify some classes purely from the pixel values, without any contextual information. Using this approach, the best results were obtained for water and vegetation classes.
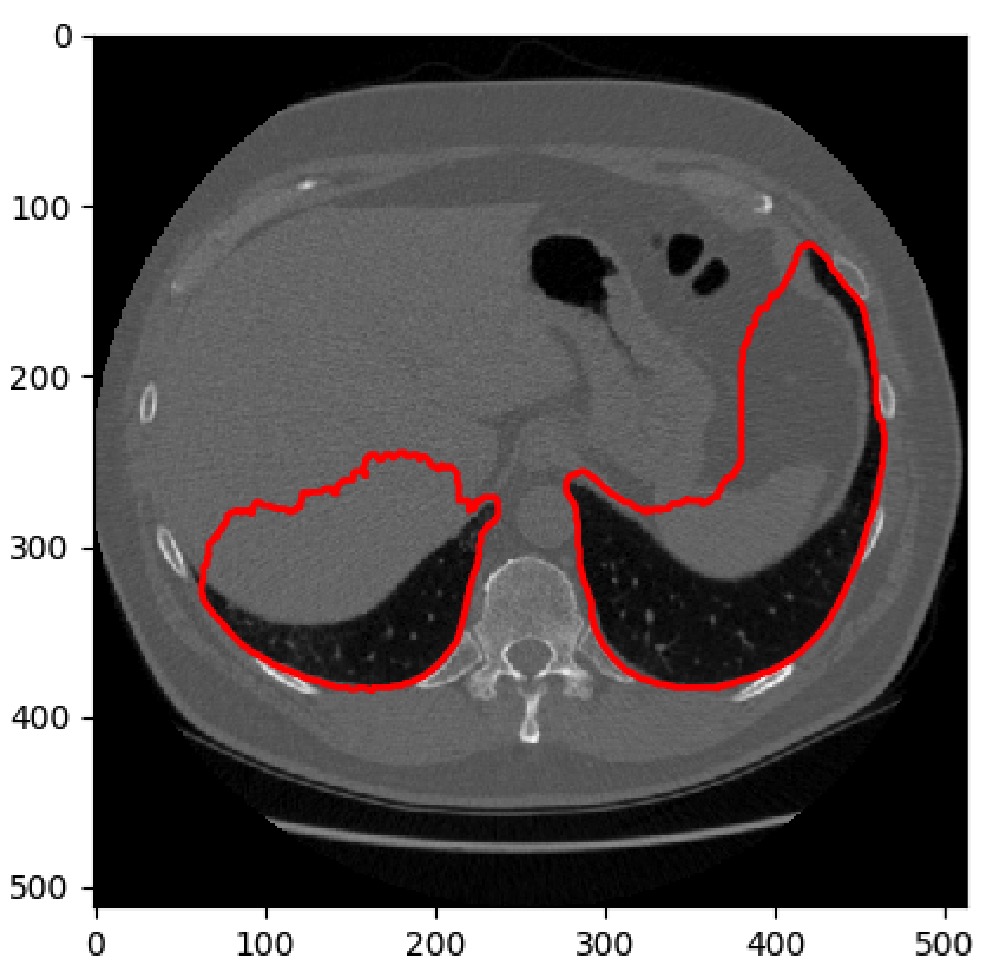
For instance, in our final solution both water classes were segmented using NDWI, which is just a ratio of the difference and sum of the pixel values in the green and infrared channels.
![]()
![]()
This image demonstrates high intensity values for waterways, but it also shows false positives on some buildings – perhaps due to the relative similarity of the specific heat of metal roofs and water.
We expected a deep learning approach to perform as well as or even better than index thresholding and, in vegetation prediction, neural networks did indeed outperform indices. However, we found that indices allow us to achieve better results for under-represented classes such as waterways and standing water. In the provided images, ponds were smaller than rivers, so we additionally thresholded our predictions by area of water body to distinguish waterways from standing water.
Third idea: Neural Networks
As we mentioned before classes are very different and given the lack of data beating top 10% score with a single model would be very tough. Instead, we decided to train a separate network for each class, except water and cars.
We tried a lot of various network architectures and settled on a modified U-net that previously had shown very good results in the problem of Ultrasound Nerve Segmentation. We had a lot of hope for Tiramisu, but its convergence was slow and performance wasn’t satisfactory enough.
We used Nadam Optimizer (Adam with Nesterov momentum) and trained the network for 50 epochs with a learning rate of 1e-3 and additional 50 epochs with a learning rate of 1e-4. Each epoch was trained on 400 batches, each batch containing 128 image patches. Each batch was created randomly cropping 112x112 patches from original images. In addition each patch was modified by applying a random transformation from group D4.
Initially we tried 224x224 but due to limited GPU memory this would significantly reduce the batch size from 128 to 32. Larger batches proved to be more important than a larger receptive field. We believe that was due to the train set containing 25 images only, which differ from one another quite heavily. As a result, we decided to trade-off receptive field size in favour of a larger batch size.
Fourth idea: what do we feed to networks
If we just had RGB data and nothing else the problem would be much simpler. We would just crop big images into batches and feed them into a network. But we have RGB, P, M and A bands which have different color depth, resolution and could be shifted in time and space. All of them may contain unique and useful information that needs to be used.
After tackling this problem in a bunch of different ways we ended up dropping A-band, M was stretched from 800x800 to 3600x3600 and stacked it with RGB and P images.
Deep neural networks can find the interactions between different features when the amount of the data is sufficient, but we suspected that for this problem it was not the case. In the recent Allstate competition, quadratic features improved performance of xgboost, which is very efficient at finding feature interactions as well. We followed a similar path and added the indices CCCI, EVI, SAVI, NDWI as four extra channels. We like to think of these extra channels as an added domain knowledge.
We suspect that these indices would not enhance performance on larger dataset.
![]()
Fifth idea: loss function
As already mentioned, the evaluation metric for this competition was an Average Jaccard Index. A common loss function for classification tasks is categorical cross entropy but in our case classes are not mutually exclusive and using binary cross entropy makes more sense. But we can go deeper. It is well known that in order to get better results your evaluation metric and your loss function need to be as similar as possible. The problem here however is that Jaccard Index is not differentiable. One can generalize it for probability prediction, which on one hand, in the limit of the very confident predictions, turns into normal Jaccard and on the other hand is differentiable – allowing the usage of it in the algorithms that are optimized with gradient descent.
That logic led us to the following loss function:
![]()
![]()
Sixth idea: local boundary effects
It is pretty clear how to prepare the patches for training - we just crop them from the original images, augment and feed into the network with the structure that we described above.
What about predictions? In the zeroth order approximation everything looks straightforward, partition (3600, 3600) image into small patches, make prediction and stitch them together.
We did this and got something like this:
![]()
Why do we have this weird square structure? And the answer is that not all outputs in the Fully Connected Networks are equally good. Number of ways that you can get from any input pixel to the central part of the output in a network is much higher than to the edge ones. As a result prediction quality is decreasing when you move away from center. We checked this hypothesis for a few classes, and, for example, for buildings logloss vs distance from center looks like this:
![]()
One way to deal with such issue was to make the predictions on overlapping patches, and crop them on the edges, but we came out with a better way. We added Cropping2D layer to the output layers of our networks, which solved two problem simultaneously:
- Losses on boundary artefacts were not back-propagated through the network;
- Edges of the predictions were cropped automatically.
As a bonus, the trick slightly decreased the computation time.
To summarize, we trained a separate model for each of the first six classes. Each of them took matrix with a shape (128, 16, 112, 112) as an input and returned the mask for a central region of the input images (128, 1, 80, 80) as an output.
![]()
Seventh idea: global boundary effect
Are we done with the boundary effects? Not yet. To partition original images into (112, 112) tiles we added zeros to the edges of the original (3600, 3600) images, classical ZeroPadding. This added some problems at the prediction time. For example, sharp change in pixel values from central to zero padded area was probably interpreted by a network as a wall of the building and as a result we got a layer of building all over the perimeter in the predicted mask.
This issue was addressed with the same trick as in the original U-net paper. We added reflections of the central part to the padded areas.
![]()
We also considered modifying zero padding layers within a network to pad with reflections instead of zeros in a similar manner. Theoretically, this micro optimization may improve overall network performance, but we did not check it.
Eighth idea: test time augmentation
At this stage we already had a strong solution that allowed to get in top 10. But you can always go deeper. If it is possible to augment your train set to increase its size, you can always perform test time augmentation to decrease variance of the predictions.
We did it in the following way:
1. Original (3600, 3600) image is rotated by 90 degrees and we get 2 images: original and rotated.
2. Both are padded.
3. Split into tiles.
4. We perform predictions on each tile.
5. Combine predictions back into the original size.
6. Crop padding areas.
7. Prediction of the rotated image is rotated back to the original orientation.
8. Results of the both prediction pipelines averaged with geometric mean.
A schematic representation of the prediction pipeline:
![]()
How does it improve our predictions?
1. We decrease variance of the predictions.
2. Images are split in tiles in a different way and this helps to decrease local boundary effects.
We used 4 image orientations for test time augmentation, but one can do it with all eight elements of the D4 group. In general, any augmentation that can be used at the train time can be also used at the test time.
After all of these steps we managed to get something which looks surprisingly nice:
![]()
We finished 8th on the Public Leaderboard and 3rd on the Private.
Many thanks to Artem Yankov, Egor Panfilov, Alexey Romanov, Sarah Bieszad and Galina Malovichko for help in preparation of this article.
More from this team
Vladimir gave a talk based on his team's winning approach in this competition at the SF Kagglers meetup in April. Check out the video below!
















































 Fair enough, I have a lot of domain knowledge and prior experience in this area.
Fair enough, I have a lot of domain knowledge and prior experience in this area.









































 . And no significant improvement could be achieved by tuning of the parameters. In order to enhance the quality, feature engineering had to be performed. Seemed like no one had done it because the top solution had slightly better score than mine.
. And no significant improvement could be achieved by tuning of the parameters. In order to enhance the quality, feature engineering had to be performed. Seemed like no one had done it because the top solution had slightly better score than mine.
 . First of all, the images were rescaled to the size of
. First of all, the images were rescaled to the size of  . Then PCA was applied. The components were added to the set of previously extracted features.
. Then PCA was applied. The components were added to the set of previously extracted features. 
 principle components. This approach showed
principle components. This approach showed  .
. .
.  and the rest had
and the rest had  . However, I found several objects with uncertainty in a prediction like this:
. However, I found several objects with uncertainty in a prediction like this:


 .
.

 - number of objects and classes respectively,
- number of objects and classes respectively,  is the prediction and
is the prediction and  is the indicator:
is the indicator:  if object
if object  is in class
is in class  , otherwise it equals to
, otherwise it equals to  . That’s it. All the labels are correct.
. That’s it. All the labels are correct.





































 , and then solves for the ratings via least squares. The Massey ratings are a compact way of encoding some of the structure of the network of the roughly 350 Division I teams. They take into account who has beaten who, and by how much, for all games played by all teams.
, and then solves for the ratings via least squares. The Massey ratings are a compact way of encoding some of the structure of the network of the roughly 350 Division I teams. They take into account who has beaten who, and by how much, for all games played by all teams.